Estruturas internas – HOBT
- Dataside

- 27 de ago. de 2016
- 5 min de leitura
Atualizado: 6 de nov. de 2025
Fala galera, hoje quero iniciar uma serie de posts sobre estruturas internas do SQL Server, bom pra iniciar essa serie quero falar sobre HOBT, para você que já brinca bastante com SQL Server em algum momento já deve ter visto ou escutado falar sobre esse termo, e se você ainda não conhece vai conhecer agora.
HOBT (Não tem relação com ‘The Hobbit’ o filme rs) é um acrônimo para Heap or BTree que são estruturas de dados composta por paginas de dados.
Quando falamos de Heap estamos falando de uma tabela sem índice Cluster, onde não temos ordenação de dados, as paginas são mapeadas pela IAM(Index Allocation Map) e são lidas na ordem de alocação.
Uma tabela sem índice Cluster, mas que possui índices Não Cluster também é considerada uma tabela Heap, pois sua estrutura principal esta desornada e sem a estrutura Btree, a tabela só deixa de ser Heap após a criação de um índice Cluster(Apenas um por tabela).
USE master GO IF(SELECT DB_ID(‘DB_TESTE’)) IS NOT NULL BEGIN DROP DATABASE DB_TESTE END GO CREATE DATABASE DB_TESTE GO USE DB_TESTE GO IF(SELECT OBJECT_ID(‘DADOS’)) IS NOT NULL BEGIN DROP TABLE DADOS END GO CREATE TABLE DADOS (CAMPO1 INT ,CAMPO2 INT ,CAMPO3 INT) GO INSERT INTO DADOS VALUES ((SELECT CAST(RAND() * 1000 AS INT)),(SELECT CAST(RAND() * 1000 AS INT)),(SELECT CAST(RAND() * 1000 AS INT))) GO 10000
No script acima estamos preparando um ambiente para mostrar como funciona de verdade essas duas estruturas de armazenamento, criamos então um banco de dados DB_TESTE, e uma tabela DADOS com 3 campos inteiros sem nenhum índice, ou seja ela será uma estrutura Heap, logo após inserindo 10000 linhas.

Como podemos ver nossa tabela DADOS possui 28 paginas de dados, e esta sobre uma estrutura Heap, na estrutura Heap não temos ordenação dos dados.

Logo se os dados são desordenados a unica maneira de acesso a uma tabela na estrutura Heap é ‘Table Scan’, onde todas as linhas são lidas para qualquer operação de acesso a dados dessa tabela, sendo uma operação muito custosa para tabelas com muita informação, porém ‘Table Scan’ geralmente é mais rápido que um Clustered Index Scan, pois ele utiliza-se da pagina IAM para escanear a tabela.

Como podemos ver no Select acima, estamos fazendo um filtro no ‘campo1’ para retornar apenas os valores 289, foram retornados 2 resultados para essa consulta, porém com o auxilio do ‘SET STATISTICS IO’ conseguimos ver que ele leu as 28 paginas de dados da nossa tabela.

Através do comando DBCC IND podemos ver as paginas que estão alocadas para nossa tabela DADOS, destaque para primeira pagina com ‘PageType = 10’ essa é nossa pagina IAM, ‘Index Allocation Map’ é uma pagina de 8KB que contém ponteiros para as extents (conjunto de 8 paginas 64 kb), tabelas grandes podem conter mais de uma pagina IAM, uma pagina IAM pode mapear em torno de 4GB de extents, então se sua tabela for relativamente grande ela irá conter mais de uma pagina IAM e elas serão ligadas entre si, ou seja cada IAM tem o endereço da próxima IAM e o da anterior (Lista duplamente ligada).
Bom como havia comentado anteriormente na estrutura Heap o unico metodo de acesso é ‘Table Scan’ onde ele irá ler as paginas de acordo com o mapeamento da pagina IAM, acima podemos ver que as paginas de dados não contém ponteiros para a próxima pagina e nem para anterior nos campos ‘NextPage’ e ‘PrevPage’, com isso podemos dizer que na estrutura Heap não temos fragmentação de dados, pois ela sempre irá ler na ordem da pagina IAM, sem fragmentação aumenta a chance de utilização do read-ahead.

Imagem retirada do BOL(Books Online), essa é uma representação de uma tabela na estrutura HEAP.
Falamos um pouco da estrutura Heap que é uma tabela sem índice Cluster e sem ordenação de dados, vamos falar um pouco da estrutura BTree(Arvore Balanceada e não Arvore Binária) onde temos a ordenação dos dados dentro das paginas de dados e temos uma estrutura diferente da Heap, onde os dados são armazenados em um formato de uma arvore com 3 níveis de navegação sendo Raiz, intermediário e nível folha, as paginas do índice são ligadas entre si, ou seja uma lista duplamente ligada, assim como as paginas IAM, como no exemplo da imagem abaixo.

Imagem retirada do BOL(Books Online).
Bom vamos incluir um índice Cluster na nossa tabela e verificar como ela vai ficar.
CREATE CLUSTERED INDEX IDX_DADOS ON DADOS(CAMPO1) GO SELECT O.NAME AS TABLE_NAME,P.INDEX_ID, I.NAME AS INDEX_NAME , AU.TYPE_DESC AS ALLOCATION_TYPE, AU.DATA_PAGES, PARTITION_NUMBER,* FROM SYS.ALLOCATION_UNITS AS AU JOIN SYS.PARTITIONS AS P ON AU.CONTAINER_ID = P.PARTITION_ID JOIN SYS.OBJECTS AS O ON P.OBJECT_ID = O.OBJECT_ID JOIN SYS.INDEXES AS I ON P.INDEX_ID = I.INDEX_ID AND I.OBJECT_ID = P.OBJECT_ID WHERE O.NAME = N’DB_TESTE’ OR O.NAME = N’DADOS’ ORDER BY O.NAME, P.INDEX_ID; GO SELECT * FROM SYS.INDEXES WHERE object_id = object_id(‘DADOS’)
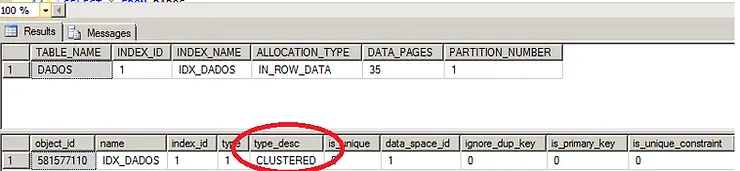

Agora podemos ver que o tipo da nossa tabela é ‘Clustered’, rodando novamente o Select sem nenhuma clausula de ordenação já podemos ver que nossos dados agora estão ordenados pelo ‘CAMPO1’.

Rodando novamente aquela consulta com o filtro buscando apenas o valor 289 podemos ver que o numero de paginas lidas são apenas 2(Pagina do Índice e a pagina de dados nível folha).

Novamente rodando o DBCC IND, destacando as duas primeiras linhas, onde a primeira é nossa pagina IAM e a segunda com ‘PageType = 2’ é a pagina do nosso índice e podemos ver que nosso índice tem apenas 2 níveis pois nossa tabela contém poucos dados. Essa pagina de índice contem informações sobre a nossa chave e qual pagina determina informação se encontra.
Note também que conforme a imagem la em cima da estrutura do Clustered Index, as paginas são uma lista duplamente ligada, então nas colunas ‘NextPage’ e ‘PrevPage’ temos um ponteiro indicando qual é a próxima pagina e a anterior, podemos ver também que elas estão ordenadas, mas isso pode mudar, caso venha a fragmentar essa tabela.

Com a ajuda do DBCC PAGE conseguimos investigar melhor nossa pagina de índice(303), como mencionei acima através dessa pagina conseguimos identificar onde esta determinada informação, por exemplo no nosso Select que esta la em cima, filtramos o ‘CAMPO1 = 289’, através dessa pagina de índice consigo identificar facilmente que meu registro 289 se encontra na pagina de dados 337 conforma acima, eu sei que meu registro 289 esta entre o registro 262 e o 301, portanto ele esta na pagina de dados 337, nesse nível do índice encontramos apenas as colunas que fazem parte da nossa chave, como passamos a clausula (*) no nosso Select precisaremos ler a pagina folha do índice também para recuperarmos os demais campos da tabela.

Acima o DUMP da nossa pagina de índice Cluster(337), esse é nosso nível Folha aonde se encontram todas as colunas. Então podemos ver que na estrutura BTree com a ajuda das paginas intermediarias podemos encontrar facilmente uma informação especifica navegando pelos níveis superiores até chegar no nível folha onde se encontra a informação.
Devemos tomar muito cuidado na escolha da chave do nosso índice, uma escolha ruim pode degradar a performance do seu ambiente.
Então quando falamos de ‘Índice Cluster’ não estamos falando apenas de Índices, mas da própria tabela em si em uma estrutura BTree.
Obs.: Os comandos ‘DBCC IND’ e ‘DBCC PAGE’ são comandos não documentados pela Microsoft.
Bom galera essa é a primeira parte, quero fazer mais posts voltados a estrutura dos índices, a ideia aqui era mostrar a diferença entre as estruturas Heap or BTree(HOBT), não entrei em detalhes sobre as vantagens e desvantagens das suas utilizações, pois a minha ideia é fazer mais posts sobre isso, o que eu queria mostrar é a diferença entre as estruturas e dar um norte para quem quer estudar mais afundo, qualquer dúvida deixe seu comentário e espero que tenham gostado.
Referencias:
HEAP \ IAM
https://blogs.msdn.microsoft.com/fcatae/2016/04/26/dbcc-ind/
Clustered Index Scan
https://blogs.msdn.microsoft.com/fcatae/2016/05/03/dbcc-indexdefrag/
Clustered Index
https://technet.microsoft.com/en-us/library/ms177443%28v=sql.105%29.aspx?f=255&MSPPError=-2147217396
HEAP
https://technet.microsoft.com/en-us/library/ms188270(v=sql.105).aspx
Reginaldo Silva



Comentários